Loss¶
ReHLine supports a variety of convex PLQ loss functions for both classification and regression tasks.
Usage Pattern¶
Define a loss function using a dictionary:
# name (str): name of the custom loss function
# loss_kwargs: more keys and values for loss parameters
loss = {'name': <loss_name>, **loss_kwargs}
Classification¶
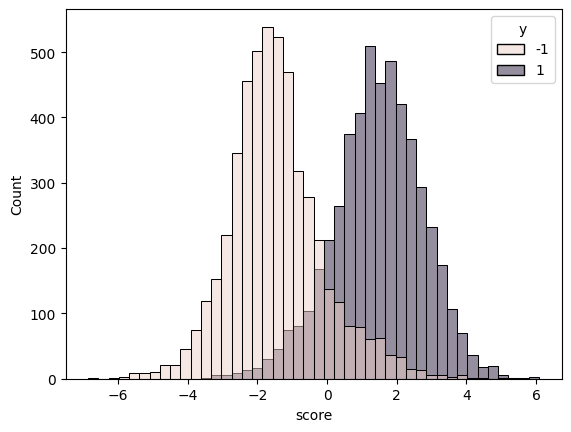
SVM (Hinge Loss)¶
Standard Support Vector Machine loss [1].
Names:
'hinge','svm','SVM'Parameters: None
loss = {'name': 'SVM'}
Related Example
Smooth SVM¶
A smoothed version of the Hinge loss (using ReHU) that is differentiable everywhere.
Names:
'sSVM','smooth SVM','smooth hinge'Parameters: None
loss = {'name': 'sSVM'}
Related Example
Squared SVM¶
Squared Hinge loss.
Names:
'squared SVM','squared svm','squared hinge'Parameters: None
loss = {'name': 'squared SVM'}
Related Example
Regression¶
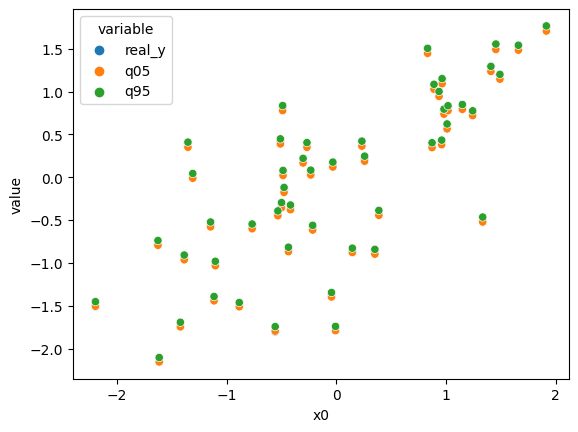
Quantile Regression¶
Minimizes the check loss (pinball loss) for estimating conditional quantiles [2].
Names:
'check','quantile','QR'- Parameters:
qt(float): The target quantile (e.g., 0.5 for median).
loss = {'name': 'QR', 'qt': 0.25}
Related Example
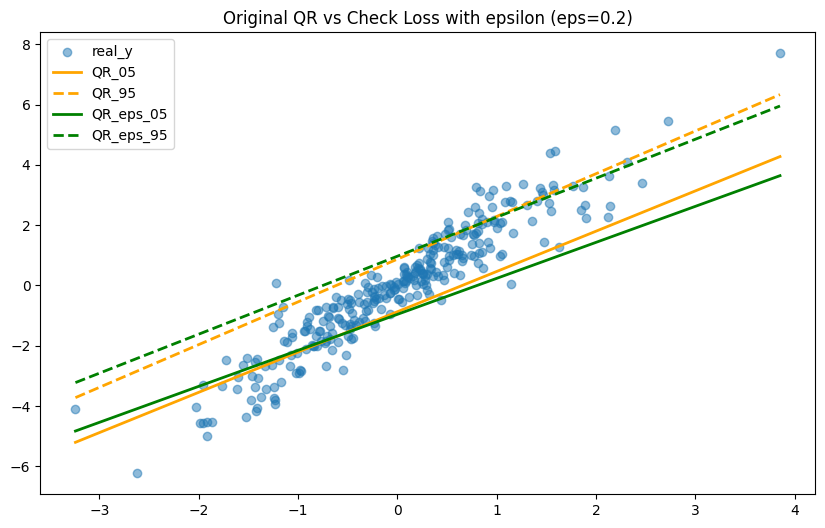
Quantile Regression with Epsilon Tolerance¶
Minimizes the check loss with an epsilon-insensitive zone for robust conditional quantile estimation.
Names:
'check_eps','quantile_eps','QR_eps'- Parameters:
qt(float): The target quantile (e.g., 0.5 for median).epsilon(float): The tolerance parameter defining the insensitive zone.
loss = {'name': 'check_eps', 'qt': 0.25, 'epsilon': 0.1}
Related Example
Huber Regression¶
Robust regression loss that is quadratic for small errors and linear for large errors [3].
Names:
'huber','Huber'- Parameters:
tau(float, default=1.0): The threshold parameter controlling the transition from quadratic to linear.
loss = {'name': 'huber', 'tau': 1.0}
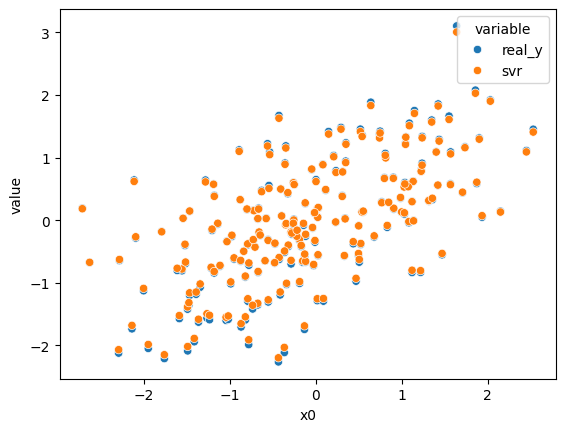
Support Vector Regression (SVR)¶
Epsilon-insensitive loss [4].
Names:
'SVR','svr'- Parameters:
epsilon(float): The epsilon-tube width.
loss = {'name': 'svr', 'epsilon': 0.1}
Related Example
Mean Absolute Error (MAE)¶
L1 loss, robust to outliers.
Names:
'MAE','mae','mean absolute error'Parameters: None
loss = {'name': 'mae'}
Mean Squared Error (MSE)¶
Standard L2 loss (Least Squares).
Names:
'MSE','mse','mean squared error'Parameters: None
loss = {'name': 'mse'}